UNIT-V: Testing Strategies
A strategic to software testing, Strategic issues
Test strategies for conventional software, Object oriented software
Validation testing, System testing
The art of debugging Testing tactics
Software testing fundamentals
White-box testing, Basis path testing
Control structure testing, Black-box testing
OO-testing methods
A strategic to software testing, Strategic issues
Software testing is a critical element of software quality assurance and represents the ultimate review of specification, design, and code generation.
Software testing fundamentals define the overriding objectives for software testing.
Testing Objectives
Glen Myers states a number of rules that can serve well as testing objectives:
Testing is a process of executing a program with the intent of finding an error.
A good test case is one that has a high probability of finding an as-yet-undiscovered error.
A successful test is one that uncovers an as-yet-undiscovered error.
If testing is conducted successfully (according to the objectives stated previously), it will uncover errors in the software
Software Testing Principles:
All tests should be traceable to customer requirements.
The objective of software testing is to uncover errors.
It follows that the most severe defects are those that cause the program to fail to meet its requirements.
Tests should be planned long before testing begins. Test planning can begin as soon as the requirements model is complete. Detailed definition of test cases can begin as soon as the design model has been solidified. Therefore, all tests can be planned and designed before any code has been generated.
The Pareto principle applies to software testing. Stated simply, the Pareto principle implies that 80 percent of all errors uncovered during testing will likely be traceable to 20 percent of all program components. The problem, of course, is to isolate these suspect components and to thoroughly test them.
Testing should begin “in the small” and progress toward testing “in the large.” The first tests planned and executed generally focus on individual components
As testing progresses, focus shifts in an attempt to find errors in integrated clusters of components and ultimately in the entire system.
Exhaustive testing is not possible. The number of path permutations for even a moderately sized program is exceptionally large. For this reason, it is impossible to execute every combination of paths during testing. It is possible, however, to adequately cover program logic and to ensure that all conditions in the component-level design have been exercised.
To be most effective, testing should be conducted by an independent third party. By most effective, we mean testing that has the highest probability of finding errors (the primary objective of testing).
The software engineer who created the system is not the best person to conduct all tests for the software.
Kaner, Falk, and Nguyen suggest the following attributes of a “good” test:
A good test has a high probability of finding an error. To achieve this goal, the tester must understand the software and attempt to develop a mental picture of how the software might fail. For example, one class of potential failure in a GUI (graphical user interface) is a failure to recognize proper mouse position. A set of tests would be designed to exercise the mouse in an attempt to demonstrate an error in mouse position recognition.
A good test is not redundant. Testing time and resources are limited. There is no point in conducting a test that has the same purpose as another test. Every test should have a different purpose
For example, a module of the Safe Home software (discussed in earlier chapters) is designed to recognize a user password to activate and deactivate the system. In an effort to uncover an error in password input, the tester designs a series of tests that input a sequence of passwords. Valid and invalid passwords (four numeral sequences) are input as separate tests.
Valid/invalid password should probe a different mode of failure. For example, the invalid password 1234 should not be accepted by a system programmed to recognize 8080 as the valid password. If it is accepted, an error is present. Another test input, say 1235, would have the same purpose as 1234 and is therefore redundant. However, the invalid input 8081 or 8180 has a subtle difference, attempting to demonstrate that an error exists for passwords “close to” but not identical with the valid password.
A good test should be “best of breed”
In a group of tests that have a similar intent, time and resource limitations may mitigate toward the execution of only a subset of these tests. In such cases, the test that has the highest likelihood of uncovering a whole class of errors should be used.
A good test should be neither too simple nor too complex. Although it is sometimes possible to combine a series of tests into one test case, the possible side effects associated with this approach may mask errors. In general, each test should be executed separately.
Testing is a set of activities that can be planned in advance and conducted systematically. For this reason a template for software testing a set of steps into which we can place specific test case design techniques and testing methods—should be defined for the software process.
A number of software testing strategies have been proposed in the literature. All provide the software developer with a template for testing and all have the following generic characteristics:
Testing begins at the component level2 and works "outward" toward the integration of the entire computer-based system.
Different testing techniques are appropriate at different points in time.
Testing is conducted by the developer of the software and (for large projects) an independent test group.
Testing and debugging are different activities, but debugging must be accommodated in any testing strategy.
Strategic Approach to Software Testing
A strategy for software testing must accommodate low-level tests that are necessary to verify that a small source code segment has been correctly implemented as well as high-level tests that validate major system functions against customer requirements. A strategy must provide guidance for the practitioner and a set of milestones for the manager.
Verification and Validation
Software testing is one element of a broader topic that is often referred to as
Verification and validation (V&V)
Verification refers to the set of activities that ensure that software correctly implements a specific function.
Validation refers to a different set of activities that ensure that the software that has been built is traceable to customer requirements.
Boehm states this in another way:
Verification: "Are we building the product right?"
Validation: "Are we building the right product?"
The definition of V&V encompasses many of the activities that we have referred to as Software Quality Assurance (SQA).
Verification and validation encompasses a wide array of SQA activities that include formal technical reviews, quality and configuration audits, performance monitoring, simulation, feasibility study, documentation review, database review, algorithm analysis, development testing, qualification testing, and installation testing.
A Software Testing Strategy
The software engineering process may be viewed as the spiral illustrated in Figure
Initially, system engineering defines the role of software and leads to software requirements analysis, where the information domain, function, behaviour, performance, constraints, and validation criteria for software are established.
Moving inward along the spiral, we come to design and finally to coding.
To develop computer software, we spiral inward along streamlines that decrease the level of abstraction on each turn.
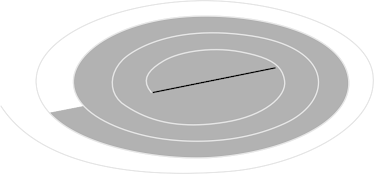
A strategy for software testing may also be viewed in the context of the spiral
Unit testing begins at the vortex of the spiral and concentrates on each unit (i.e., component) of the software as implemented in source code.
Testing progresses by moving outward along the spiral to integration testing, where the focus is on design and the construction of the software architecture
Taking another turn outward on the spiral, we encounter validation testing, where requirements established as part of software requirements analysis are validated against the software that has been constructed.
Finally, we arrive at system testing, where the software and other system elements are tested as a whole.
To test computer software, we spiral out along stream- lines that broaden the scope of testing with each turn
 s
sStrategic Issues:
Specify product requirements in a quantifiable manner long before testing commences.
The overriding objective of testing is to find errors; a good testing strategy also assesses other quality characteristics such as portability, maintainability, and usability.
State testing objectives explicitly
The specific objectives of testing should be stated in measurable terms.
For example, test effectiveness, test coverage, mean time to failure, the cost to find and fix defects, remaining defect density or frequency of occurrence, and test work-hours per regression test all should be stated within the test plan.
Understand the users of the software and develop a profile for each user category.
Use-cases that describe the interaction scenario for each class of user that can reduce overall testing effort by focusing testing on actual use of the product
Develop a testing plan that emphasizes “rapid cycle testing.”
Gilb recommends that a software engineering team “learn to test in rapid cycles (2 percent of project effort) of customer-useful, at least field ‘trial able,’ increments of functionality and/or quality improvement.”
The feedback generated from these rapid cycle tests can be used to control quality levels and the corresponding test strategies.
Build “robust” (robustness is the ability of a computer system to cope with errors during execution and cope with erroneous input.) software that is designed to test itself.
Software should be designed in a manner that uses anti bugging techniques. That is, software should be capable of diagnosing certain classes of errors. In addition, the design should accommodate automated testing and regression testing.
Use effective formal technical reviews as a filter prior to testing.
Formal technical reviews can be as effective as testing in uncovering errors. For this reason, reviews can reduce the amount of testing effort that is required to produce high-quality software.
Conduct formal technical reviews to assess the test strategy and test cases themselves. Formal technical reviews can uncover inconsistencies, omissions, and outright errors in the testing approach. This saves time and also improves product quality
Develop a continuous improvement approach for the testing process. The test strategy should be measured.
The metrics collected during testing should be used as part of a statistical process control approach for software testing.
Software testing includes all topics of Software testing such as Methods such as Black Box Testing, White Box Testing, Visual Box Testing and Gray Box Testing.
Levels such as Unit Testing, Integration Testing, Regression Testing, Functional Testing, System Testing, Acceptance Testing, Alpha Testing, Beta Testing, Non-Functional testing, Security Testing, Portability Testing.

Validation Testing
The art of debugging Testing tactics
Debugging is the practice of finding existing bugs in your code once they have reared their ugly heads in the form of failures when your program is running. It may involve any of the following, as well as other techniques:
Inspecting the source for errors
Examining program output to try to identify patterns
Using a “debugger,” a piece of software designed for this purpose
Logging program state as it runs to detect inconsistencies
Tests help you identify problems in your code before they are buried deep in your program and difficult to diagnose. If you write your tests along side your code development, you can hopefully prevent the bugs from piling up too deeply in the first place.
Unit testing
Unit testing focuses verification effort on the smallest unit of software design, the software component or module. Using the component-level design description as a guide, important control paths are tested to uncover errors within the boundary of the module.
The relative complexity of tests and uncovered errors is limited by the constrained scope established for unit testing.
The unit test is white-box oriented, and the step can be conducted in parallel for multiple components.
Unit Test Considerations
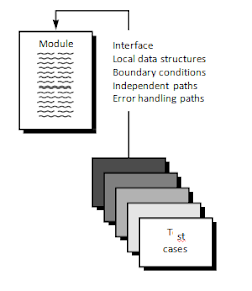
The tests that occur as part of unit tests are illustrated schematically.
In Figure the module interface is tested to ensure that information properly flows into and out of the program unit under test.
The local data structure is examined to ensure that data stored temporarily maintains its integrity during all steps in an algorithm's execution.
Boundary conditions are tested to ensure that the module operates properly at boundaries established to limit or restrict processing.
All independent paths (basis paths) through the control structure are exercised to ensure that all statements in a module have been executed at least once. And finally, all error handling paths are tested.
The more common errors in computation are
(1) Misunderstood or incorrect arithmetic precedence,
(2) Mixed mode operations,
(3) Incorrect initialization,
(4) Precision inaccuracy,
(5) Incorrect symbolic representation of an expression.
Comparison and control flow are closely coupled to one another
White Box Testing:
White-box testing, sometimes called glass-box testing is a test case design method that uses the control structure of the procedural design to derive test cases.
Using white-box testing methods, the software engineer can derive test cases that
(1) Guarantee that all independent paths within a module have been exercised at least once,
(2) Exercise all logical decisions on their true and false sides,
(3) Execute all loops at their boundaries and within their operational bounds, and
(4) Exercise internal data structures to ensure their validity.
Logic errors and incorrect assumptions are inversely proportional to the probability that a program path will be executed.
Errors tend to creep into our work when we design and implement function, conditions, or control that is out of the mainstream.
Everyday processing tends to be well understood (and well scrutinized), while "special case" processing tends to fall into the cracks.
We often believe that a logical path is not likely to be executed when; it may be executed on a regular basis.
The logical flow of a program is some- times counterintuitive, meaning that our unconscious assumptions about flow of control and data may lead us to make design errors that are uncovered only once path testing commences.
Typographical errors are random. When a program is translated into programming language source code, it is likely that some typing errors will occur. Many will be uncovered by syntax and type checking mechanisms, but others may go undetected until testing begins. It is as likely that a typo will exist on an obscure logical path as on a mainstream path.
Each of these reasons provides an argument for conducting white-box tests
Basis path testing:
Basis path testing is a white-box testing technique first proposed by Tom McCabe. The basis path method enables the test case designer to derive a logical complexity measure of a procedural design and use this measure as a guide for defining a basis set of execution paths.
Test cases derived to exercise the basis set are guaranteed to execute every statement in the program at least one time during testing.
Control Flow Testing (Flow Graph Notation)
Before the basis path method can be introduced, a simple notation for the representation of control flow, called a flow graph (or program graph) must be introduced.
The flow graph depicts logical control flow using the notation illustrated in Figure
The structured constructs in flow graph form
Where each circle represents one or more non branching PDL or source code statements
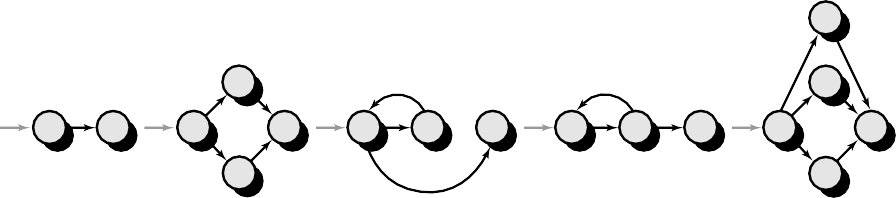
When compound conditions are encountered in a procedural design, the generation of a flow graph becomes slightly more complicated. A compound condition occurs when one or more Boolean operators (logical OR, AND, NAND, NOR) is present in a conditional statement.
Cyclomatic Complexity:
Cyclomatic complexity is software metric that provides a quantitative measure of the logical complexity of a program. When used in the context of the basis path testing method, the value computed for cyclomatic complexity defines the number of inde pendent paths in the basis set of a program and provides us with an upper bound for the number of tests that must be conducted to ensure that all statements have been executed at least once.
An independent path is any path through the program that introduces at least one new set of processing statements or a new condition.
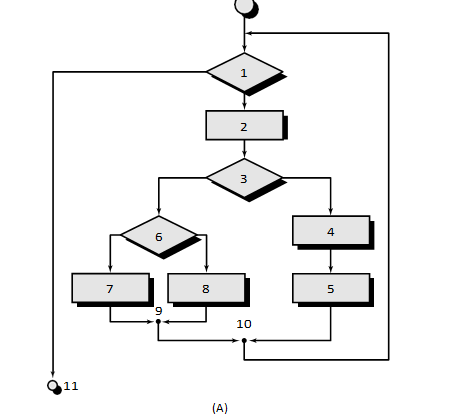
For example, a set of independent paths for the flow graph illustrated in the above Figure is
path 1: 1-11
path 2: 1-2-3-4-5-10-1-11
path 3: 1-2-3-6-8-9-10-1-11
path 4: 1-2-3-6-7-9-10-1-11
Note that each new path introduces a new edge.
The path 1-2-3-4-5-10-1-2-3-6-8-9-10-1-11 is not considered to be an independent path because it is simply a combination of already specified paths and does not traverse any new edges.
Cyclomatic complexity has a foundation in graph theory and provides us with extremely useful software metric. Complexity is computed in one of three ways:
The number of regions of the flow graph corresponds to the cyclomatic Complexity.
Cyclomatic complexity, V(G), for a flow graph, G, is defined as
V (G) = E — N + 2
Where E is the number of flow graph edges, N is the number of flow graph nodes.
3. Cyclomatic complexity, V(G), for a flow graph, G, is also defined as
V (G) = P + 1
Where P is the number of predicate nodes contained in the flow graph G.
Referring once more to the flow graph in Figure the cyclomatic complexity can be computed using each of the algorithms just noted:
The flow graph has four regions.
V (G) = 11 edges — 9 nodes + 2 = 4.
V (G) = 3 predicate nodes + 1 = 4.
Control Structure Testing:
The basis path testing technique is one of a number of techniques for control structure testing. Although basis path testing is simple and highly effective, it is not sufficient in itself. Control structure testing broadens testing coverage and improves quality of white-box testing.
Condition Testing
Condition testing is a test case design method that exercises the logical conditions contained in a program module. A simple condition is a Boolean variable or a relational expression, possibly preceded with one NOT (¬) operator. A relational expression takes the form E1 <relational-operator> E2
Where E1 and E2 are arithmetic expressions A compound condition is composed of two or more simple conditions, Boolean operators, and parentheses. We assume that Boolean operators allowed in a compound condition include OR (|), AND (&) and NOT (¬). A condition without relational expressions is referred to as a Boolean expression. Therefore, the possible types of elements in a condition include a Boolean operator, a Boolean variable, a pair of Boolean parentheses (surrounding a simple or com- pound condition), a relational operator, or an arithmetic expression.
If a condition is incorrect, then at least one component of the condition is incorrect
Therefore, types of errors in a condition include the following:
Boolean operator error (incorrect/missing/extra Boolean operators).
Boolean variable error.
Boolean parenthesis error.
Relational operator error.
Arithmetic expression error.
The condition testing method focuses on testing each condition in the program. Condition testing strategies generally have two advantages. First, measurement of test coverage of a condition is simple.
Second, the test coverage of conditions in a program provides guidance for the generation of additional tests for the program.
The purpose of condition testing is to detect not only errors in the conditions of a program but also other errors in the program.
Data Flow Testing
The data flow testing method selects test paths of a program according to the locations of definitions and uses of variables in the program. A number of data flow testing strategies have been studied and compared.
To illustrate the data flow testing approach, assume that each statement in a program is assigned a unique statement number and that each function does not modify its parameters or global variables.
Data flow testing strategies are useful for selecting test paths of a program containing nested if and loop statements
Loop Testing
Loops are the cornerstone for the vast majority of all algorithms implemented in soft- ware. And yet, we often pay them little heed while conducting software tests.
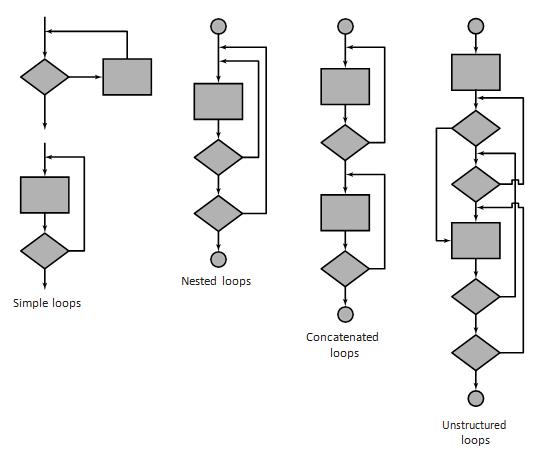
Loop testing is a white-box testing technique that focuses exclusively on the validity of loop constructs. Four different classes of loops [BEI90] can be defined: simple loops, concatenated loops, nested loops, and unstructured loops
Simple loops: The following set of tests can be applied to simple loops, where n is the maximum number of allowable passes through the loop.
Skip the loop entirely.
Only one passes through the loop.
Two passes through the loop.
m passes through the loop where m < n.
n —1, n, n + 1 passes through the loop.
Nested loops:
If we were to extend the test approach for simple loops to nested loops, the number of possible tests would grow geometrically as the level of nesting increases. This would result in an impractical number of tests. Beizer suggests an approach that will help to reduce the number of tests:
Start at the innermost loop. Set all other loops to minimum values.
Conduct simple loop tests for the innermost loop while holding the outer loops at their minimum iteration parameter (e.g., loop counter) values. Add other tests for out-of-range or excluded values.
Work outward, conducting tests for the next loop, but keeping all other outer loops at minimum values and other nested loops to "typical" values.
Continue until all loops have been tested.
Black-box testing
Black Box testing, also called behavioural testing, focuses on the functional requirements of the software.
Black Box testing enables the software engineer to derive sets of input conditions that will fully exercise all functional requirements for a program.
Black-box testing is not an alternative to white-box techniques. Rather, it is a complementary approach that is likely to uncover a different class of errors than white-box methods.
Black-box testing attempts to find errors in the following categories:
(1) Incorrect or missing functions,
(2) Interface errors,
(3) Errors in data structures or external data base access,
(4) Behaviour or performance errors, and
(5) Initialization and termination errors.
Black- box testing tends to be applied during later stages of testing.
Because black-box testing purposely disregards control structure, attention is focused on the information domain
By applying black-box techniques, we derive a set of test cases that satisfy the following criteria
(1) Test cases that reduce, by a count that is greater than one, the number of additional test cases that must be designed to achieve reasonable testing and
(2) Test cases that tell us something about the presence or absence of classes of errors, rather than an error associated only with the specific test at hand.
Equivalence Partitioning
Equivalence partitioning is a black-box testing method that divides the input domain of a program into classes of data from which test cases can be derived. An ideal test case single-handedly uncovers a class of errors (e.g., incorrect processing of all character data) that might otherwise require many cases to be executed before the general error is observed. Equivalence partitioning strives to define a test case that uncovers classes of errors, thereby reducing the total number of test cases that must be developed.
Equivalence classes may be defined according to the following guidelines:
If an input condition specifies a range, one valid and two invalid equivalence classes are defined.
If an input condition requires a specific value, one valid and two invalid equivalence classes are defined.
If an input condition specifies a member of a set, one valid and one invalid equivalence class are defined.
If an input condition is Boolean, one valid and one invalid class are defined.
Boundary Value Analysis
A greater number of errors tend to occur at the boundaries of the input domain rather than in the "center." It is for this reason that boundary value analysis (BVA) has been developed as a testing technique. Boundary value analysis leads to a selection of test cases that exercise bounding values.
Boundary value analysis is a test case design technique that complements equivalence partitioning. Rather than selecting any element of an equivalence class, BVA leads to the selection of test cases at the "edges" of the class. Rather than focusing solely on input conditions, BVA derives test cases from the output domain as well.
Guidelines for BVA are similar in many respects to those provided for Equivalence partitioning:
System Testing:
System testing falls under Black box testing as it includes testing of the external working of the software. Testing follows user's perspective to identify minor defects.
System Testing includes testing of a fully integrated software system. Generally, a computer system is made with the integration of software (any software is only a single element of a computer system). The software is developed in units and then interfaced with other software and hardware to create a complete computer system. In other words, a computer system consists of a group of software to perform the various tasks, but only software cannot perform the task; for that software must be interfaced with compatible hardware. System testing is a series of different type of tests with the purpose to exercise and examine the full working of an integrated software computer system against requirements.
System Testing includes the following steps.
Verification of input functions of the application to test whether it is producing the expected output or not.
Testing of integrated software by including external peripherals to check the interaction of various components with each other.
Testing of the whole system for End to End testing.
Integration Testing:
Integration testing is a systematic technique for constructing the program struc- ture while at the same time conducting tests to uncover errors associated with inter- facing. The objective is to take unit tested components and build a program structure that has been dictated by design.
All components are combined in advance. The entire program is tested as a whole. A set of errors is encountered. Correction is difficult because isolation of causes is complicated by the vast expanse of the entire program. Once these errors are corrected, new ones appear and the process continues in a seemingly endless loop
Top-down Integration
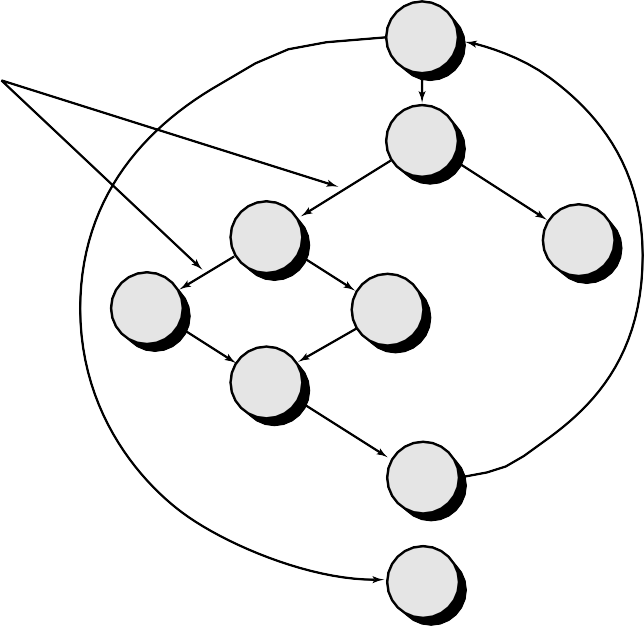
Top-down integration testing is an incremental approach to construction of program structure. Modules are integrated by moving downward through the control hierar- chy, beginning with the main control module (main program). Modules subordinate (and ultimately subordinate) to the main control module are incorporated into the structure in either a depth-first or breadth-first manner.
Referring to Figure depth-first integration would integrate all components on a major control path of the structure. Selection of a major path is somewhat arbitrary and depends on application-specific characteristics. For example, selecting the left- hand path, components M1, M2 , M5 would be integrated first. Next, M8 or M6 would be integrated. Then, the central and right- hand control paths are built. Breadth-first integration incorporates all components directly subordinate at each level, moving across the structure horizontally. From the figure, components M2, M3, and M4 (a replacement for stub S4) would be integrated first. The next control level, M5, M6, and so on, follows.

Figure: Top down Approach
The integration process is performed in a series of five steps:
The main control module is used as a test driver and stubs are substituted for all components directly subordinate to the main control module.
Depending on the integration approach selected (i.e., depth or breadth first), subordinate stubs are replaced one at a time with actual components.
Tests are conducted as each component is integrated.
On completion of each set of tests, another stub is replaced with the real component.
Regression testing may be conducted to ensure that new errors have not been introduced.
The process continues from step 2 until the entire program structure is built.
Bottom-up Integration:
Bottom-up integration testing, as its name implies, begins construction and testing with atomic modules Because components are integrated from the bottom up, processing required for components subordinate to a given level is always available and the need for stubs is eliminated.
A bottom-up integration strategy may be implemented with the following steps:
Low-level components are combined into clusters (sometimes called builds) that perform a specific software sub function.
A driver (a control program for testing) is written to coordinate test case input and output.
The cluster is tested.
Drivers are removed and clusters are combined moving upward in the pro- gram structure.
Integration follows the pattern illustrated in Figure Components are com- bined to form clusters 1, 2, and 3. Each of the clusters is tested using a driver (shown as a dashed block). Components in clusters 1 and 2 are subordinate to Ma. Drivers D1 and D2 are removed and the clusters are interfaced directly to Ma. Similarly, driver D3 for cluster 3 is removed prior to integration with module Mb. Both Ma and Mb will ultimately be integrated with component Mc, and so forth.

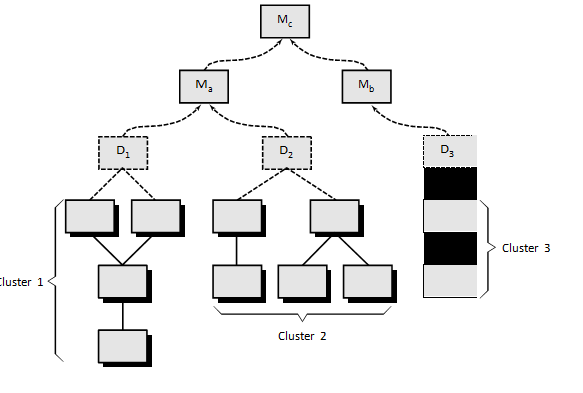
Fig: Bottom up Approach
As integration moves upward, the need for separate test drivers lessens. In fact, if the top two levels of program structure are integrated top down, the number of drivers can be reduced substantially and integration of clusters is greatly simplified
Validation Testing:
At the culmination of integration testing, software is completely assembled as a pack- age, interfacing errors have been uncovered and corrected, and a final series of soft- ware tests—validation testing—may begin. Validation can be defined in many ways, but a simple (albeit harsh) definition is that validation succeeds when software functions in a manner that can be reasonably expected by the customer.
The specification contains a section called Validation Criteria. Information contained in that section forms the basis for a validation testing approach.
The process of evaluating software during the development process or at the end of the development process to determine whether it satisfies specified business requirements.
Validation Testing ensures that the product actually meets the client's needs. It can also be defined as to demonstrate that the product fulfils its intended use when deployed on appropriate environment.
It answers to the question, Are we building the right product?
Validation Testing - Workflow:
Validation testing can be best demonstrated using V-Model. The Software/product under test is evaluated during this type of testing.
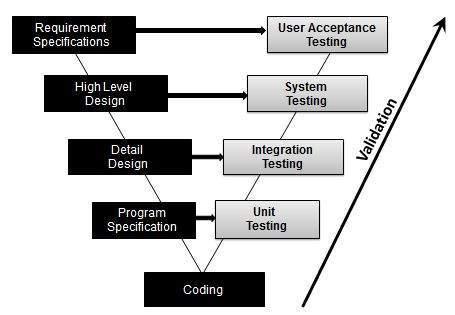
Activities:
Unit Testing
Integration Testing
System Testing
User Acceptance Testing
Validation Test Criteria
Software validation is achieved through a series of black-box tests that demonstrate conformity with requirements. A test plan outlines the classes of tests to be conducted and a test procedure defines specific test cases that will be used to demonstrate conformity with requirements.
Both the plan and procedure are designed to ensure that all functional requirements are satisfied, all behavioral characteristics are achieved, all performance requirements are attained, documentation is correct, and human- engineered and other requirements are met (e.g., transportability, compatibility, error recovery, maintainability).
After each validation test case has been conducted, one of two possible conditions exist:
(1) The function or performance characteristics conform to specification and are accepted or
(2) a deviation from specification is uncovered and a deficiency list is created. Deviation or error discovered at this stage in a project can rarely be corrected prior to scheduled delivery.
Configuration Review:
An important element of the validation process is a configuration review. The intent of the review is to ensure that all elements of the software configuration have been properly developed, are cataloged, and have the necessary detail to bolster the sup- port phase of the software life cycle. The configuration review, sometimes called an audit, has been discussed in more detail in Chapter 9.
Alpha and Beta Testing
Instructions for use may be misinterpreted; strange combinations of data may be regularly used; output that seemed clear to the tester may be unintelligible to a user in the field.
When custom software is built for one customer, a series of acceptance tests are conducted to enable the customer to validate all requirements. Conducted by the end- user rather than software engineers, an acceptance test can range from an informal "test drive" to a planned and systematically executed series of tests.
In fact, acceptance testing can be conducted over a period of weeks or months, thereby uncovering cumulative errors that might degrade the system over time.
If software is developed as a product to be used by many customers, it is impractical to perform formal acceptance tests with each one. Most software product builders use a process called alpha and beta testing to uncover errors that only the end-user seems able to find.
The alpha test is conducted at the developer's site by a customer. The software is used in a natural setting with the developer "looking over the shoulder" of the user and recording errors and usage problems. Alpha tests are conducted in a controlled environment.
The beta test is conducted at one or more customer sites by the end-user of the software. Unlike alpha testing, the developer is generally not present. Therefore, the beta test is a "live" application of the software in an environment that cannot be con- trolled by the developer. The customer records all problems (real or imagined) that are encountered during beta testing and reports these to the developer at regular intervals. As a result of problems reported during beta tests, software engineers make modifications and then prepare for release of the software product to the entire customer base.
Recovery Testing
Many computer based systems must recover from faults and resume processing within a pre specified time. In some cases, a system must be fault tolerant; that is, processing faults must not cause overall system function to cease. In other cases, a system failure must be corrected within a specified period of time or severe economic dam- age will occur.
Recovery testing is a system test that forces the software to fail in a variety of ways and verifies that recovery is properly performed. If recovery is automatic (performed by the system itself), re initialization, check pointing mechanisms, data recovery, and restart are evaluated for correctness. If recovery requires human intervention, the mean-time-to-repair (MTTR) is evaluated to determine whether it is within accept- able limits.
Security Testing
Any computer-based system that manages sensitive information or causes actions that can improperly harm (or benefit) individuals is a target for improper or illegal penetration. Penetration spans a broad range of activities: hackers who attempt to penetrate systems for sport; disgruntled employees who attempt to penetrate for revenge; dishonest individuals who attempt to penetrate for illicit personal gain.
Security testing attempts to verify that protection mechanisms built into a system will, in fact, protect it from improper penetration. To quote Beizer [BEI84]: "The sys- tem's security must, of course, be tested for invulnerability from frontal attack—but must also be tested for invulnerability from flank or rear attack."
During security testing, the tester plays the role(s) of the individual who desires to penetrate the system. Anything goes! The tester may attempt to acquire passwords
Given enough time and resources, good security testing will ultimately penetrate a system. The role of the system designer is to make penetration cost more than the value of the information that will be obtained.
Stress Testing
During earlier software testing steps, white-box and black-box techniques resulted in thorough evaluation of normal program functions and performance. Stress tests are designed to confront programs with abnormal situations. In essence, the tester who performs stress testing asks: "How high can we crank this up before it fails?"
Stress testing executes a system in a manner that demands resources in abnormal quantity, frequency, or volume. For example,
(1) Special tests may be designed that generate ten interrupts per second, when one or two is the average rate,
(2) Input data rates may be increased by an order of magnitude to determine how input functions will respond,
(3) Test cases that require maximum memory or other resources are executed,
(4) Test cases that may cause thrashing in a virtual operating system are designed,
(5) Test cases that may cause excessive hunting for disk-resident data are created. Essentially, the tester attempts to break the program.
A variation of stress testing is a technique called sensitivity testing. In some situations (the most common occur in mathematical algorithms), a very small range of data contained within the bounds of valid data for a program may cause extreme and even erroneous processing or profound performance degradation. Sensitivity testing attempts to uncover data combinations within valid input classes that may cause instability or improper processing.
Performance Testing
For real-time and embedded systems, software that provides required function but does not conform to performance requirements is unacceptable. Performance testing is designed to test the run-time performance of software within the context of an integrated system. Performance testing occurs throughout all steps in the testing process. Even at the unit level, the performance of an individual module may be assessed as white-box tests are conducted. However, it is not until all system elements are fully integrated that the true performance of a system can be ascertained. Performance tests are often coupled with stress testing and usually require both hardware and software instrumentation. That is, it is often necessary to measure resource utilization (e.g., processor cycles) in an exacting fashion
The art of Debugging:
Software testing is a process that can be systematically planned and specified. Test case design can be conducted, a strategy can be defined, and results can be evaluated against prescribed expectations.
Debugging occurs as a consequence of successful testing. That is, when a test case uncovers an error, debugging is the process that results in the removal of the error. Although debugging can and should be an orderly process, it is still very much an art. A software engineer, evaluating the results of a test, is often confronted with a "symptomatic" indication of a software problem. That is, the external manifestation of the error and the internal cause of the error may have no obvious relationship to one another. The poorly understood mental process that connects a symptom to a cause is debugging.
The Debugging Process
Debugging is not testing but always occurs as a consequence of testing.
the debugging process begins with the execution of a test case. Results are assessed and a lack of correspondence between expected and actual perfor- mance is encountered.
In many cases, the non corresponding data are a symptom
a few characteristics of bugs provide some clues:
The symptom and the cause may be geographically remote. That is, the symptom may appear in one part of a program, while the cause may actually be located at a site that is far removed.
Highly coupled program structures The symptom may disappear (temporarily) when another error is corrected.
The symptom may actually be caused by non errors The symptom may be caused by human error that is not easily traced.
The symptom may be a result of timing problems, rather than processing problems.
It may be difficult to accurately reproduce input conditions (e.g., a real-time application in which input ordering is indeterminate).
The symptom may be intermittent. This is particularly common in embedded systems that couple hardware and software inextricably.
The symptom may be due to causes that are distributed across a number of tasks running on different processors
OO-testing methods
Software typically undergoes many levels of testing, from unit testing to system or acceptance testing.
Typically, in-unit testing, small “units”, or modules of the software, are tested separately with focus on testing the code of that module. In higher, order testing (e.g., acceptance testing), the entire system is tested with the focus on testing the functionality or external behaviour of the system.
As information systems are becoming more complex, the object-oriented paradigm is gaining popularity because of its benefits in analysis, design, and coding. Conventional testing methods cannot be applied for testing classes because of problems involved in testing classes, abstract classes, inheritance, dynamic binding, message, passing, polymorphism, concurrency, etc.
Testing classes is a fundamentally different problem than testing functions.A function (or a procedure) has a clearly defined input-output behaviour, while a class does not have an input-output behaviour specification. We can test a method of a class using approaches for testing functions, but we cannot test the class using these approaches.
Object-Oriented systems there are following additional dependencies:
Class to class dependencies
Class to method dependencies
Class to message dependencies
Class to variable dependencies
Method to variable dependencies
Method to message dependencies
Method to method dependencies
Issues in Testing Classes:
Additional testing techniques are, therefore, required to test these dependencies. Another issue of interest is that it is not possible to test the class dynamically, only its instances i.e, objects can be tested. Similarly, the concept of inheritance opens various issues e.g., if changes are made to a parent class or superclass, in a larger system of a class it will be difficult to test subclasses individually and isolate the error to one class.
In object-oriented programs, control flow is characterized by message passing among objects, and the control flow switches from one object to another by inter-object communication. Consequently, there is no control flow within a class like functions. This lack of sequential control flow within a class requires different approaches for testing. Furthermore, in a function, arguments passed to the function with global data determine the path of execution within the procedure. But, in an object, the state associated with the object also influences the path of execution, and methods of a class can communicate among themselves through this state because this state is persistent across invocations of methods. Hence, for testing objects, the state of an object has to play an important role.
Techniques of object-oriented testing are as follows:
Fault Based Testing:
This type of checking permits for coming up with test cases supported the consumer specification or the code or both. It tries to identify possible faults (areas of design or code that may lead to errors.). For all of these faults, a test case is developed to “flush” the errors out. These tests also force each time of code to be executed.
This method of testing does not find all types of errors. However, incorrect specification and interface errors can be missed. These types of errors can be uncovered by function testing in the traditional testing model. In the object-oriented model, interaction errors can be uncovered by scenario-based testing. This form of Object oriented-testing can only test against the client’s specifications, so interface errors are still missed.
Class Testing Based on Method Testing:
This approach is the simplest approach to test classes. Each method of the class performs a well defined cohesive function and can, therefore, be related to unit testing of the traditional testing techniques. Therefore all the methods of a class can be involved at least once to test the class.Random Testing:
It is supported by developing a random test sequence that tries the minimum variety of operations typical to the behavior of the categoriesPartition Testing:
This methodology categorizes the inputs and outputs of a category so as to check them severely. This minimizes the number of cases that have to be designed.Scenario-based Testing:
It primarily involves capturing the user actions then stimulating them to similar actions throughout the test.
These tests tend to search out interaction form of error.
Comments
Post a Comment